This post is a mirror of the article I published to Detect.Gyi on Medium back in May 2024.
Introduction
One of the most critical aspects of a detection engineering program is the documentation. Without documentation, your SOC is flying blind, and are likely to triage the alert inefficiently by spending time looking at the wrong data, or at worst, misinterpreting the detection altogether and making incorrect conclusions in their triage. It's our job as the detection engineers to ensure that each detection is thoroughly documented and classified to support the analysts, as well as aide us in answering questions from the business with confidence when it comes to coverage.
In this article I'll discuss picking a knowledge base platform, or, if that's not an option, hopefully provide some ideas as to how you can adapt your own platform to suit the task. I'll then dive into the structure of the individual knowledge base articles themselves, and provide tips about the metadata you should use and how they can help you, followed by the kinds of things you should be writing for each detection.
Establishing your Knowledge Base
If you have the luxury of picking a knowledge base platform for your detection engineering program, then consider yourself lucky! Many do not have a choice, having to shape their articles around the monolithic platform their organisation has already chosen. For that reason, I'm going to talk in general terms as much as possible to accommodate the most amount of platforms, and you can adapt the layout and configuration of your articles to match the capabilities of your platform accordingly.
Your platform at a minimum should support kind of labelling or tagging. This will allow you to assign a label to an article and then use a filter or search to find articles that share that label. This feature is included in almost every platform I've encountered, and will be the mechanism for how we classify and organise our detections. If you're using Confluence, this is how you're going to have to do it until Confluence databases comes out!
If you get to pick a platform, I'd highly recommend Notion. Notion is a note-taking app that uses databases and filtered views as the primary method of organising data. We will be able to create just about any kind of metadata we want, and be able to filter it however want as well. Notion also supports best in class enterprise support with features like SSO and real time collaboration, making it highly scalable to large teams. I'll be using the free version of Notion in my personal instance for the upcoming examples.

Note: when picking a platform, you should pick something that includes integrations with your ticketing system of choice as well as your codebase. Many platforms support at least Github and Jira, but other services are not always supported.
I'll be approaching the rest of this article from a Confluence/Notion perspective, but if you are using a platform that supports any of these kinds of features, you shouldn't have any issues setting up something similar. You only might start to run into issues when building complicated filtered views later on down the track.
A Single Source of Truth
At the outset, it's important to talk to your team and establish the knowledge base as the single source of truth. Documentation must be centralised as much as possible, because when things start to leak into other platforms or formats, content becomes unfindable and unmanageable. When that happens, your SOC will struggle to trust the content in your knowledge base. It is imperative that everyone stays on the same page and knows where to look.
Creating a Metadata Schema
When writing articles for your detections, knowing what metadata you want to use is key. I'll provide some examples, but before that, think about the use-cases you might encounter as a detection engineer. For example, what if you want to see all your detections under the 'Exfiltration' MITRE tactic? What if you want to narrow that down to detections that apply to Sharepoint? Or GCP? Or both? What if you want to filter those detections to a specific platform, like Splunk? Or detections that are already deployed or in development? These are the kinds of questions you need to ask yourself when establishing a metadata structure for your articles.
Typically, detections tend to all have the same required metadata elements across any platform or use-case. We can say with relative certainty that at a minimum you should include:
-
The title of the detection
-
The criticality/severity of the detection (The severity that dictates the SLA with which your SOC should respond and triage the detection)
-
MITRE Mapping, to at least the Tactic and Technique level
-
Creation date
-
Last updated date
These will give you a solid base to work upon for more basic SOC environments, or environments where you're not supporting many platforms. This is ideal for small, internal SIEM environments.
For more advanced SOCs, or SOCs where you're looking at a breadth of customers and platforms, you might also want to consider having fields for:
-
The platform(s) the detection applies to
-
The customers who have this detection
-
The data source the detection applies to (More on this later - does your KB platform support backlinking etc. etc.)
-
A link to the relevant ticket from your Detection Engineering workflow
With all of these fields, you should be armed with the metadata you need to not only accurately filter your detections, but also get holistic insights into your coverage from multiple perspectives.
Writing up Detections
This is another section where a lot of it is going to come down to you and your team's personal preferences. You might prefer something more simplistic, maybe something more detailed, or even opt for a detection-as-code approach where you define everything in YAML. But, nonetheless, there are a few core sections that I feel are necessary for a useful detection article.
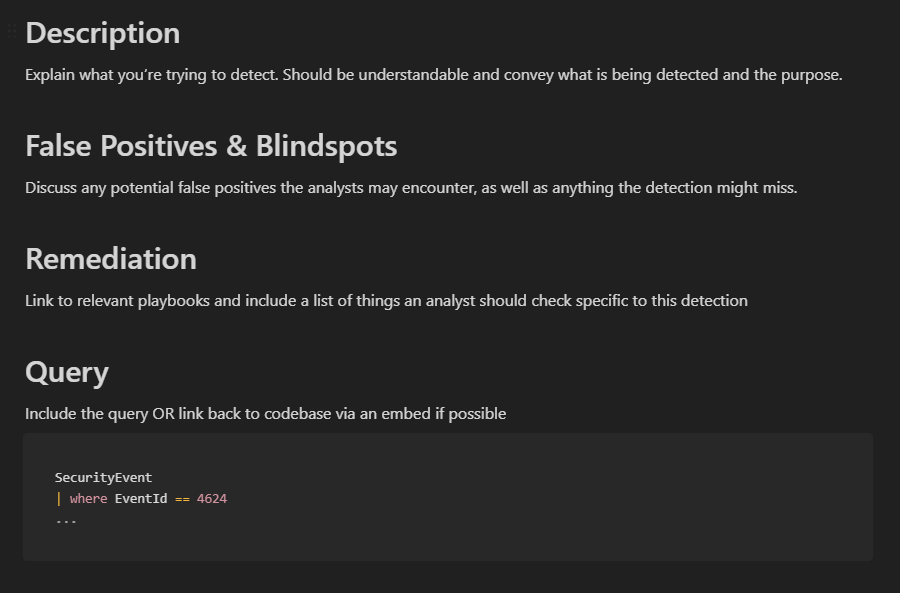
The Description
A concise description of what it is you're actually trying to detect is pivotal since you're commonly writing for a couple different audiences. You're writing primarily for your SOC analysts doing the triage, and ensuring you're on the same page about what's going on in the alert. You're also writing for the client or your internal management who might be looking at reports and escalations that come through. Ensuring everyone can understand what you're trying to detect is an art in and of itself, but nonetheless, this field is an essential for most SIEMs and consequently your knowledge base article.
As an example, I'll reference a detection that is available in Microsoft Sentinel's template gallery: Azure AD Role Management Permission Grant.

Identifies when the Microsoft Graph RoleManagement.ReadWrite.Directory (Delegated or Application) permission is granted to a service principal.
This permission allows an application to read and manage the role-based access control (RBAC) settings for your company's directory.
An adversary could use this permission to add an Azure AD object to an Admin directory role and escalate privileges. Ref : https://docs.microsoft.com/graph/permissions-reference#role-management-permissions
Ref : https://docs.microsoft.com/graph/api/directoryrole-post-members?view=graph-rest-1.0&tabs=http
This is a great description for a couple reasons:
-
Clearly tells the reader exactly what is going on. A specific Graph permission has been granted to a Service Principal.
-
It lets the reader know exactly what that permission can allow that Service Principal to do, informing the analyst's next investigation steps.
-
Provides an example of how an adversary may use it in the context of a wider compromise.
-
Optionally, it provides some references for the analyst to read further. This is a good thing, but we'll discuss some options for how you can document these references later on.
In most cases, I recommend you keep the same description between your knowledge base article and the built-in description in your SIEM alert. This keeps thing the same and will lessen any potential confusion.
False Positives & Blindspots
One thing that every detection engineer needs to be cognisant of when deploying alerts into production environments is the potential for False Positives. These should be quantified and forecasted as much as possible during the development phase, and the results of that should be written up here. You'll want analysts to be able to refer to this section during triage to clarify what could be potentially going on in the environment to trigger a false positive.
By including 'Blindspots', you can also elaborate on the gaps your detection might have. You might have a very deliberate scope, or are targeting a very specific sub-technique in MITRE, and this is something you might wish to inform the analysts of.
Remediation (Containment, Eradication, etc. etc.)
Remediation is the section where you'll actually put rubber to the road and give the analysts some investigation steps. Just like everything else in this section, the format is going to vary wildly depending on your SOC & SIEM configuration. But at a high level, I'd look at including some combination of:
-
A list of places an analyst can go to investigate further
- It might be a particularly section in an EDR/XDR portal
-
Queries that can be used to drilldown further
-
Links to playbooks or other relevant pre-defined processes that may be relevant, e.g. if it's an Execution-based detection, you might link off to a separate piece of documentation that shows how and when to invoke an incident response procedure for containing that endpoint.
Query
Oftentimes it's useful to include the query in your documentation itself. If possible, it's best to embed the query from your codebase within the page. This way, if the query is ever changed or updated, it'll always be up to date in the documentation too.
Wrapping Up
Hopefully this has given you some ideas on where to start when building out a knowledge base of your own. When I started building systems like these, I struggled to find any solid resources, so hopefully this helps fill the gap.
If you have any questions or just want to chat, feel free to reach out to myself on LinkedIn or on Twitter via @rcegann.